
2024년 현재, 인공지능(AI) 기술은 비약적으로 발전하여 다양한 분야에서 활용되고 있습니다. 특히 생성형 AI와 자연어 처리 기술은 콘텐츠 제작에 혁신을 가져왔습니다. 이번 포스팅에서는 OpenAI의 API를 활용하여 텍스트를 음성으로 변환하는 방법을 중심으로, AI를 활용한 콘텐츠 제작의 가능성을 탐구해보겠습니다.

텍스트에서 음성으로: OpenAI API의 활용
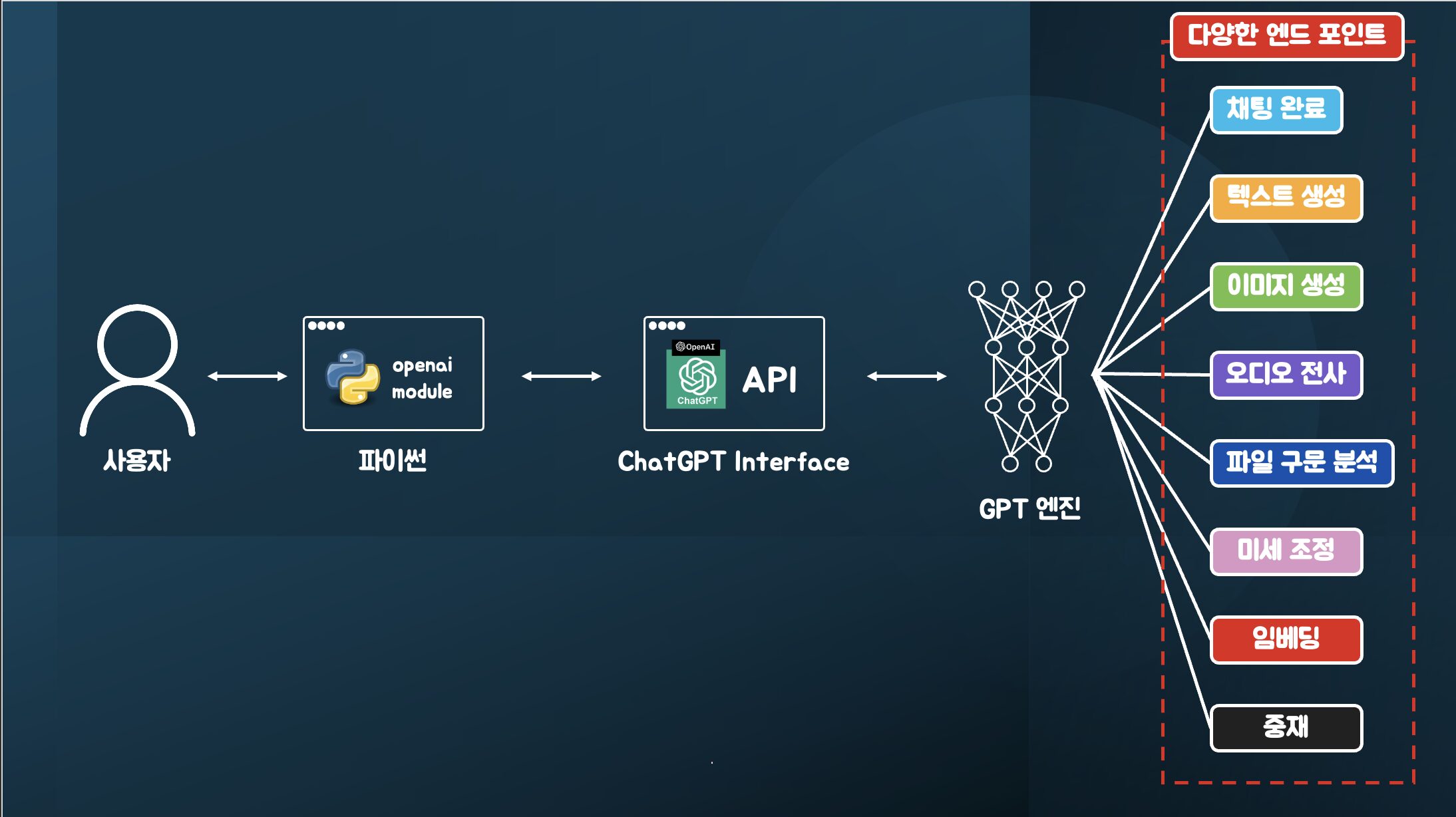
OpenAI는 다양한 언어를 지원하는 텍스트-음성 변환(TTS) API를 제공합니다. 이를 통해 블로그 포스트를 내레이션하거나, 다국어 오디오 콘텐츠를 생성할 수 있습니다. 또한, 실시간 오디오 스트리밍도 가능하여 다양한 응용 분야에서 활용될 수 있습니다.
텍스트 to 음성 변환 API의 기능
- 텍스트를 입력받아 음성 파일(mp3, flac, aac, opus 등)로 출력
- 다양한 언어 및 음성 지원
- 실시간 오디오 스트리밍
실습: OpenAI API를 사용하여 텍스트를 음성으로 변환하기
이제 실제로 OpenAI API를 사용하여 텍스트를 음성으로 변환하는 방법을 알아보겠습니다.
우선, Python 환경에서 OpenAI API를 사용할 수 있도록 설정합니다. OpenAI 라이브러리를 설치하고 API 키를 준비해야 합니다. (앞서 강의들에서 설명했으니, 참고하세요)
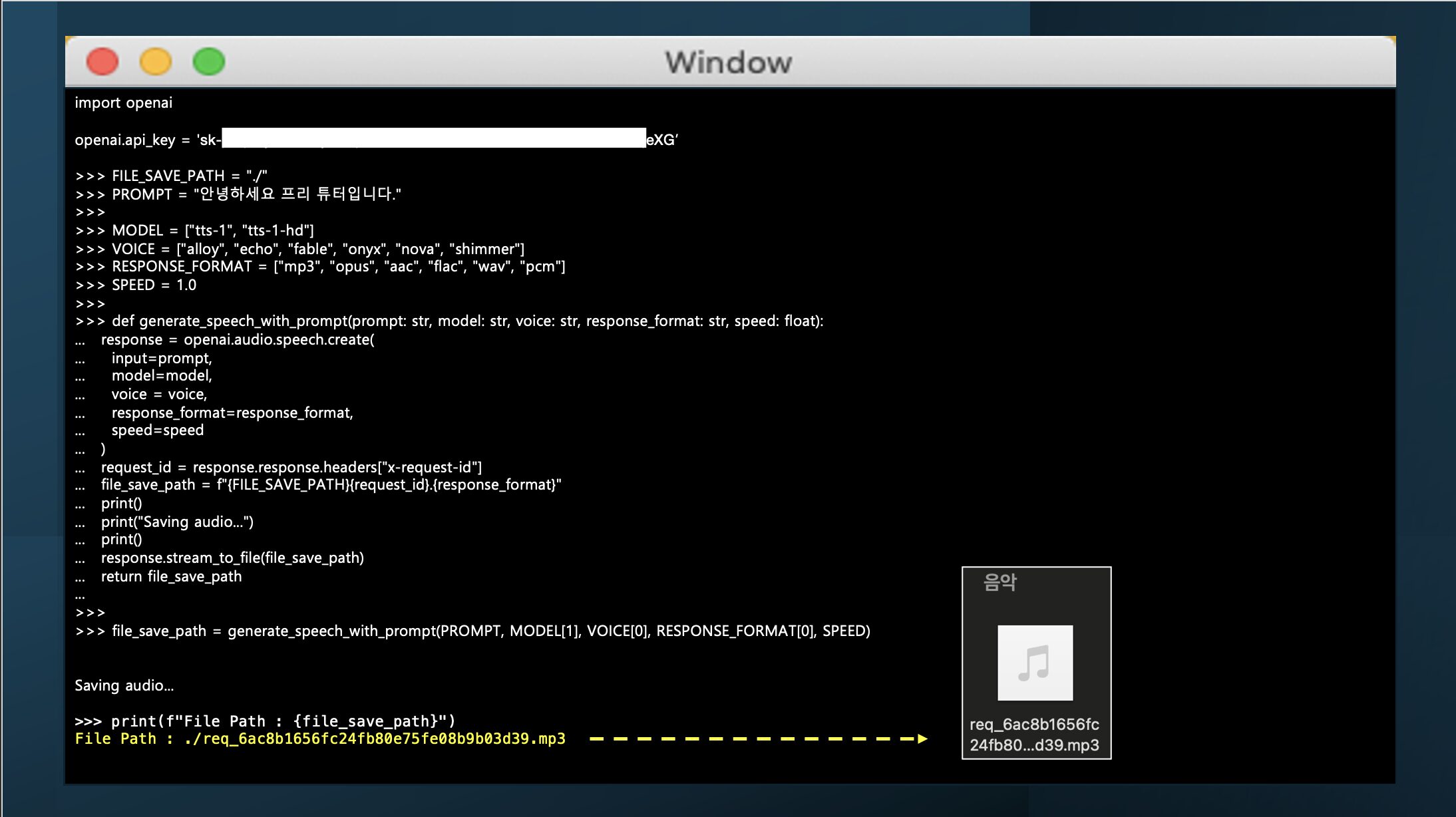
import openai
openai.api_key = "YOUR API KEY"
FILE_SAVE_PATH = "./"
PROMPT = "안녕하세요 프리 튜터입니다."
MODEL = ["tts-1", "tts-1-hd"]
VOICE = ["alloy", "echo", "fable", "onyx", "nova", "shimmer"]
RESPONSE_FORMAT = ["mp3", "opus", "aac", "flac", "wav", "pcm"]
SPEED = 1.0
def generate_speech_with_prompt(prompt: str, model: str, voice: str, response_format: str, speed: float):
response = openai.audio.speech.create(
input=prompt,
model=model,
voice = voice,
response_format=response_format,
speed=speed
)
request_id = response.response.headers["x-request-id"]
file_save_path = f"{FILE_SAVE_PATH}{request_id}.{response_format}"
print()
print("Saving audio...")
print()
response.stream_to_file(file_save_path)
return file_save_path
file_save_path = generate_speech_with_prompt(PROMPT, MODEL[1], VOICE[0], RESPONSE_FORMAT[0], SPEED)
print(f"File Path : {file_save_path}")File Path : ./req_6ac8b1656fc24fb80e75fe08b9b03d39.mp3이 예제는 텍스트를 “alloy” 음성으로 변환하고, 파일명이 중복되지 않게 request id를 추출하여 파일 명으로 설정 후, 요청한 포멧 형식으로 저장하는 과정입니다. API는 다양한 출력 포맷을 지원하므로 필요에 따라 다른 포맷을 사용할 수 있습니다.
각 옵션 설명
MODEL : 음성 품질
OpenAI는 두 가지 주요 TTS 모델을 제공합니다: tts-1과 tts-1-hd입니다.
- tts-1 : 이 모델은 실시간 애플리케이션을 위해 최적화되어 있으며, 낮은 대기 시간(low latency)을 제공합니다. 다만, 품질 면에서는 tts-1-hd에 비해 다소 떨어질 수 있으며, 특정 상황에서는 약간의 잡음이 발생할 가능성이 있습니다.
- tts-1-hd : tts-1 모델의 고품질 버전으로, 더 나은 음질을 제공합니다. 하지만, 이 모델은 tts-1에 비해 대기 시간이 더 길 수 있습니다. tts-1-hd는 일반적으로 음질을 중시하는 애플리케이션에 적합합니다.
VOICE : 지원 음성
OpenAI의 TTS API는 여섯 가지 기본 음성을 제공합니다. 각 음성은 고유한 특징을 가지고 있으며, 원하는 톤과 청중에 맞춰 선택할 수 있습니다.
- Alloy: 중립적이고 다재다능한 음성.
- Echo: 감정이 풍부한 음성.
- Fable: 이야기체에 적합한 음성.
- Onyx: 강렬하고 확신에 찬 음성.
- Nova: 부드럽고 따뜻한 음성.
- Shimmer: 밝고 명랑한 음성.
RESPONSE_FORMAT : 출력 포맷
TTS API는 다양한 출력 포맷을 지원하여 다양한 요구에 맞출 수 있습니다.
- mp3: 기본 출력 포맷으로, 대부분의 애플리케이션에 적합합니다.
- opus: 인터넷 스트리밍과 통신에 적합한 저지연 포맷.
- aac: 디지털 오디오 압축 포맷으로, YouTube, Android, iOS에서 선호됩니다.
- flac: 무손실 오디오 압축 포맷으로, 아카이빙에 적합합니다.
- wav: 비압축 WAV 오디오로, 저지연 애플리케이션에 적합합니다.
- pcm: 원시 샘플을 포함하는 포맷으로, 24kHz의 16비트 저지연 오디오를 제공합니다.
SPEED : 음성 재생 속도
TTS API의 속도 설정 값은 0.25에서 4.0까지 조절할 수 있으며, 기본값은 1.0입니다. 속도를 조절하면 생성된 음성의 재생 속도를 빠르게 또는 느리게 할 수 있습니다.
- 0.25
- 1.0
- 2.0
- 4.0
지원 언어 : 자동 설정 됨(Input text에 따라)
OpenAI의 TTS 모델은 40개 이상의 언어를 지원합니다. 주요 언어로는 영어, 스페인어, 중국어, 힌디어 등이 있으며, 각 언어의 텍스트를 입력하면 해당 언어로 음성을 생성할 수 있습니다.
생성형 AI와 텍스트-음성 변환 기술은 콘텐츠 제작의 혁신을 이끌고 있습니다. OpenAI의 강력한 API를 활용하면 누구나 손쉽게 고품질의 음성 콘텐츠를 제작할 수 있습니다. 앞으로도 AI 기술의 발전과 함께 더욱 다양한 응용 분야에서 혁신적인 콘텐츠가 탄생할 것입니다.
이 강의를 끝으로 ChatGPT와 생성형 AI를 활용한 콘텐츠 제작 가이드 과목을 마치도록 하겠습니다.
길었던 학습을 같이 해주셔서 감사합니다. 또 다른 유용한 과목에서 찾아뵙도록 하겠습니다.
#ChatGPT #GenAI #생성형 AI #음성 변환 #OpenAI API